V8 JS 引擎
V8 是一个由 Google 开发的开源 JavaScript 引擎,目前用在 Chrome 浏览器和 Node.js 中,其核心功能是执行易于人类理解的 JavaScript 代码。
其主要核心流程分为编译和执行两步。首先需要将 JavaScript 代码转换为低级中间代码或者机器能够理解的机器代码,然后再执行转换后的代码并输出执行结果。
你可以把 V8 看成是一个虚构出来的计算机,也称为虚拟机,虚拟机通过模拟实际计算机的各种功能来实现代码的执行,如模拟实际计算机的 CPU、堆栈、寄存器等,虚拟机还具有它自己的一套指令系统。
所以对��于 JavaScript 代码来说,V8 就是它的整个世界,当 V8 执行 JavaScript 代码时,你并不需要担心现实中不同操作系统的差异,也不需要担心不同体系结构计算机的差异,你只需要按照虚拟机的规范写好代码就可以了。
V8 没有采用某种单一的技术,而是混合编译执行和解释执行这两种手段,我们把这种混合使用编译器和解释器的技术称为 JIT(Just In Time)技术。这是一种权衡策略,因为这两种方法都各自有自的优缺点,解释执行的启动速度快,但是执行时的速度慢,而编译执行的启动速度慢,但是执行时的速度快。你可以参看下面完整的 V8 执行 JavaScript 的流程图:
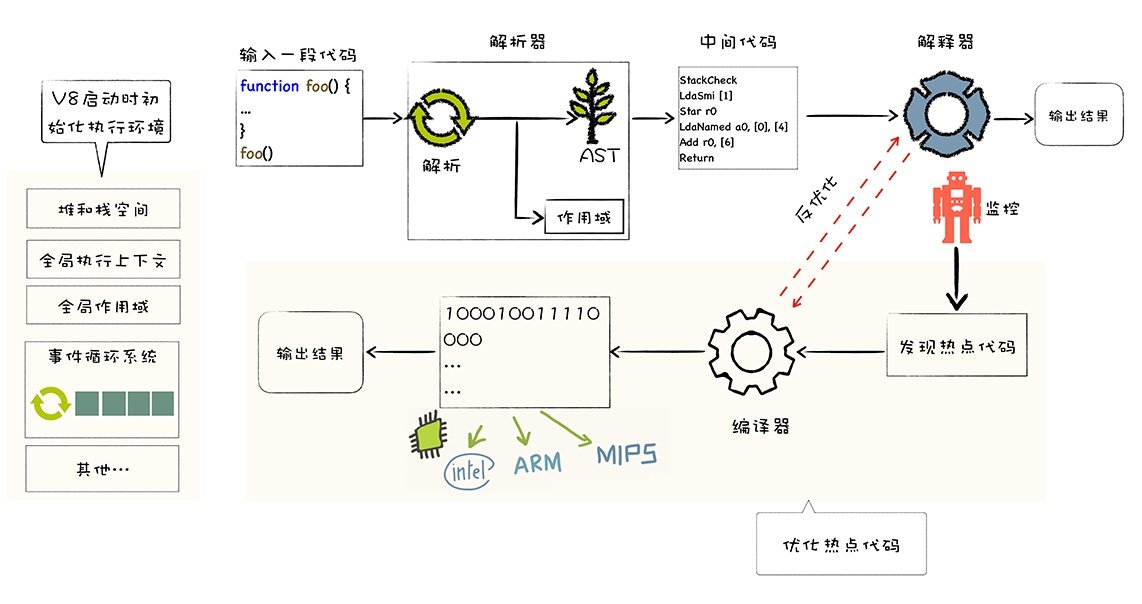
我们先看上图中的最左边的部分,在 V8 启动执行 JavaScript 之前,它还需要准备执行 JavaScript 时所需要的一些基础环境,这些基础环境包括了“堆空间”“栈空间”“全局执行上下文”“全局作用域”“消息循环系统”“内置函数”等,这些内容都是在执行 JavaScript 过程中需要使用到的,比如:
- JavaScript 全局执行上下文就包含了执行过程中的全局信息,比如一些内置函数,全局变量等信息;
- 全局作用域包含了一些全局变量,在执行过程中的数据都需要存放在内存中;
- 而 V8 是采用了经典的堆和栈的管理内存管理模式,所以 V8 还需要初始化了内存中的堆和栈结构;
- 另外,要我们的 V8 系统活起来,还需要初始化消息循环系统,消息循环系统包含了消息驱动器和消息队列,它如同 V8 的心脏,不断接受消息并决策如何处理消息。
基础环境准备好之后,接下来就可以向 V8 提交要执行的 JavaScript 代码了。
首先 V8 ��会接收到要执行的 JavaScript 源代码,不过这对 V8 来说只是一堆字符串,V8 并不能直接理解这段字符串的含义,它需要结构化这段字符串。结构化,是指信息经过分析后可分解成多个互相关联的组成部分,各组成部分间有明确的层次结构,方便使用和维护,并有一定的操作规范。
V8 源代码的结构化之后,就生成了抽象语法树(AST),我们称为 AST,AST 是便于 V8 理解的结构。
有了 AST 和作用域之后,接下来就可以生成字节码了,字节码是介于 AST 和机器代码的中间代码。但是与特定类型的机器代码无关,解释器可以直接解释执行字节码,或者通过编译器将其编译为二进制的机器代码再执行。生成了字节码之后,解释器就登场了,它会按照顺序解释执行字节码,并输出执行结果。
上图中我们在解释器附近画了个监控机器人,这是一个监控解释器执行状态的模块,在解释执行字节码的过程中,如果发现了某一段代码会被重复多次执行,那么监控机器人就会将这段代码标记为热点代码。
当某段代码被标记为热点代码后,V8 就会将这段字节码丢给优化编译器,优化编译器会在后台将字节码编译为二进制代码,然后再对编译后的二进制代码执行优化操作,优化后的二进制机器代码的执行效率会得到大幅提升。如果下面再执行到这段代码时,那么 V8 会优先选择优化之后的二进制代码,这样代码的执行速度就会大幅提升。
不过,和静态语言不同的是,JavaScript 是一种非常灵活的动态语言,对象的结构和属性是可以在运行时任意修改的,而经过优化编译器优化过的代码只能针对某种固定的结构,一旦在执行过程中,对象的结构被动态修改了,那么优化之后的代码势必会变成无效的代码,这时候优化编译器就需要执行��反优化操作,经过反优化的代码,下次执行时就会回退到解释器解释执行。
常规属性(properties)和排序属性(element)
我们先来了解什么是对象中的常规属性和排序属性,你可以先参考下面这样一段代码:
function Foo() {
this[100] = "test-100";
this[1] = "test-1";
this["B"] = "bar-B";
this[50] = "test-50";
this[9] = "test-9";
this[8] = "test-8";
this[3] = "test-3";
this[5] = "test-5";
this["A"] = "bar-A";
this["C"] = "bar-C";
}
var bar = new Foo();
for (key in bar) {
console.log(`index:${key} value:${bar[key]}`);
}
执行这段代码所打印出来的结果:
index:1 value:test-1
index:3 value:test-3
index:5 value:test-5
index:8 value:test-8
index:9 value:test-9
index:50 value:test-50
index:100 value:test-100
index:B value:bar-B
index:A value:bar-A
index:C value:bar-C
观察这段打印出来的数据,我们发现打印出来的属性顺序并不是我们设置的顺序,我们设置属性的时候是乱序设置的,比如开始先设置 100,然后有设置了 1,但是输出的内容却非常规律,总的来说体现在以下两点:
- 设置的数字属性被最先打印出来了,并且按照数字大小的顺序打印的;
- 设置的字符串属性依然是按照之前的设置顺序打印的,比如我们是按照 B、A、C 的顺序设置的,打印出来依然是��这个顺序。
之所以出现这样的结果,是因为在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。
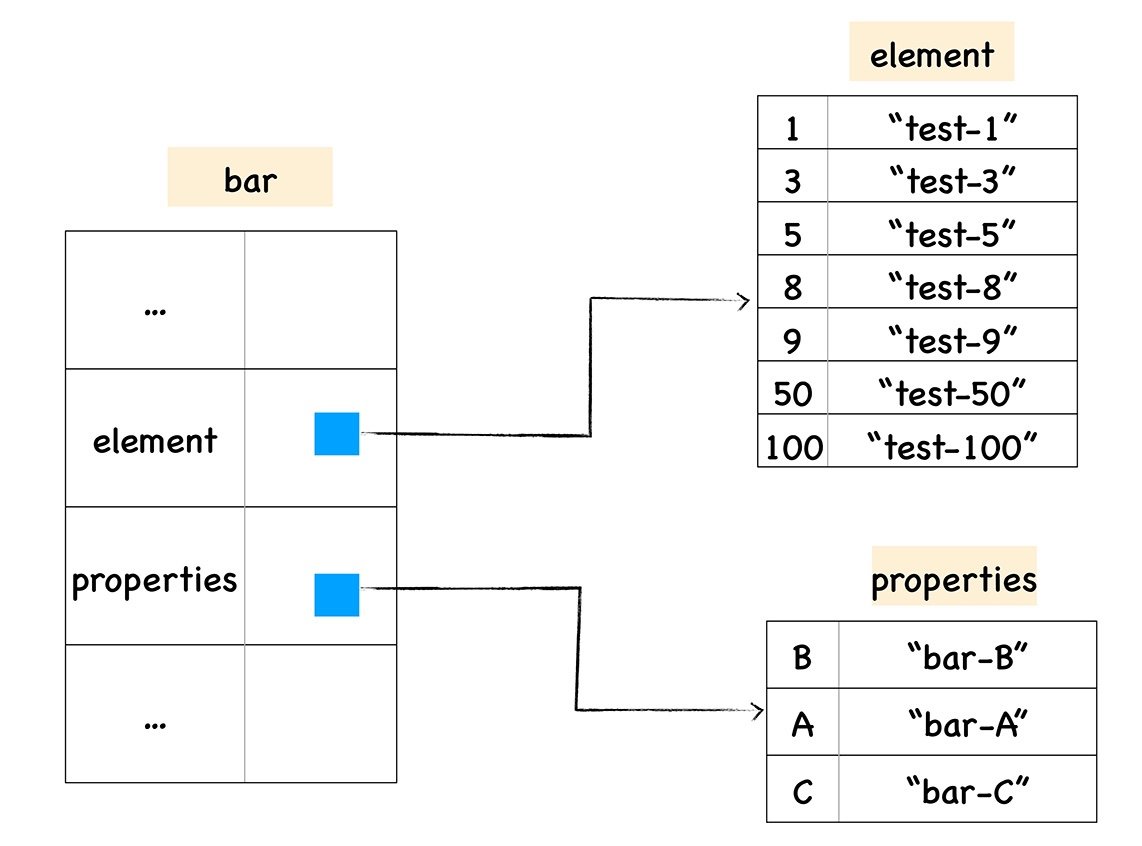
在这里我们把对象中的数字属性称为排序属性,在 V8 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性,具体结构如下图所示:
V8 调试工具 d8
函数调用
下面这三段代码会导致栈溢出么?
function foo() {
foo(); // 是否存在堆栈溢出错误?
}
foo();
function foo() {
setTimeout(foo, 0); // 是否存在堆栈溢出错误?
}
function foo() {
return Promise.resolve().then(foo);
}
foo();
通过分别执行上面三段代码后会发现,第一段会造成栈溢出的错误,第二段能够正确执行,而第三段没有栈溢出的错误,却会造成页面的卡死。其主要原因是这三段代码的底层执行逻辑是完全不同的:
- 第一段代码是在同一个任务中重复调用嵌套的 foo 函数;
- 第二段代码是使用 setTimeout 让 foo 函数在不同的任务中执行;
- 第三段代码是在同一个任务中执行 foo 函数,但是却不是嵌套执行。同一个宏任务下不断执行微任务,导致其他宏任务无法执行故造成页面卡死。